DDD - Domain Driven Design
what is DDD?
Is a software DESIGN approach where the application model is split in mutiple (bounded) contexts instead of using 1 model to model the whole design.
There is a emphasis on having regular meetings with domain experts to futher interate on the design where drawings the models and ubiquitous language are central. This is one of the fundamentals of DDD. Without this step you cannot effectively exercise DDD.
DDD is commonly subdivided into 2 spaces:
- the problem space, where you draw/discuss/iterate on the problem space, this can be done with the domain expert
- the solution space, where the actual code is implemented using some DDD concepts (entities, value objects, aggregates, bounded contexts)
In DDD there shouldn’t be a dissconnect between the internal context of the domain of the domain expert and the actual code context. They should be one as much as possible.
DDD should only be used for an application where the domain space is complex and there is a lot of moving parts. Otherwise it’s overkill. You can also implement a DDD lite by only using the problem space and implementing the rest with a REST CRUD framework.
problem space
In this space the actual problem will be discussed, iterated, drawn, interacted with, … . Each problem space will be confined to their respective bounded context.
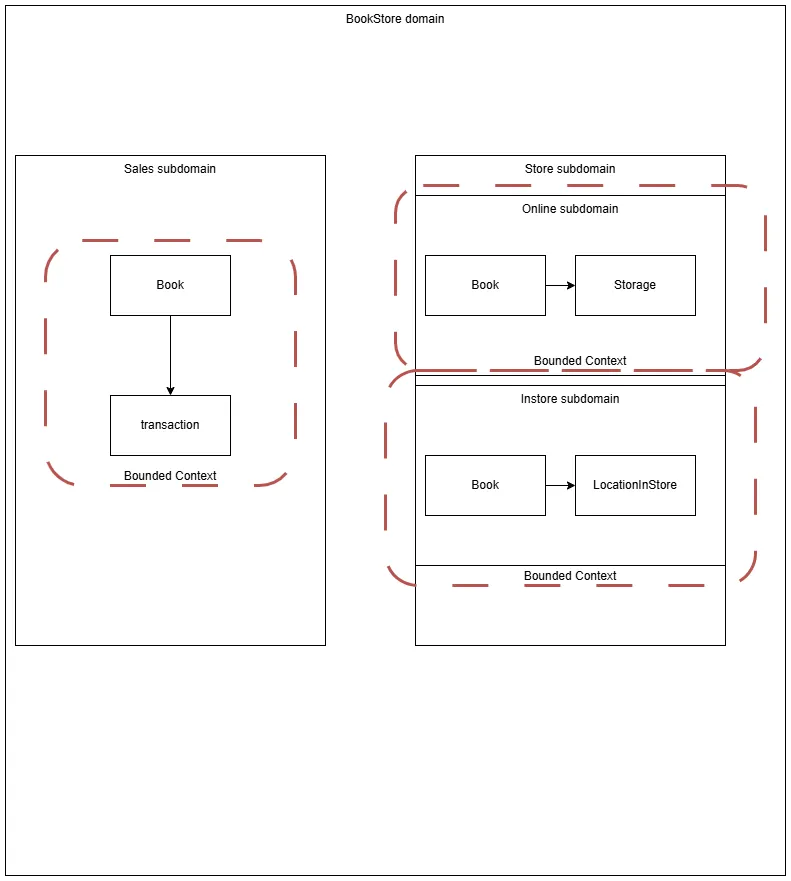
bounded context
Each bounded context should have one clearly defined ubiquitous language, there can be only one definition of a class and there should be no conflicting classes, each class should have a function and clear goal in mind WITHIN it’s bounded context.
Most of the time a bounded context is confined to one domain expert, such that only one ubiquitous language is used in the bounded context, but you are free to self-define your bounded contexts. It’s even possible to have only 1 bounded context for the whole domain but this is not recommended because you will need to have high communication between the teams.
You cannot have a bounded context in another bounded context, such construction would voilate the unique ubiquitous language requirement.
It’s recommended to only have one bounded context per team (but is not a hardline rule more a recommendation). It’s not recommanded because it’s difficult to juggle between 2 bounded contexts, you can see it as juggeling between 2 different languages (Chinese and Polish) you don’t know yet, which makes it mentally more difficult.
Often times the development teams are also subdivided in the same team as the functional teams. Also the bounded contexts are also naturally also divided in the same functional teams. Why? As you have a sales, import, … department in you company, these are divided by use case of the product. Which will naturally also have a one and the same domain expert for each. For some exceptions sometimes a department can be divided in mutiple bounded contexts.
A bounded context can contain one or mutiple subdomains.
ubiquitous language
Ubiquitous language is used to incorporate the business language used by the domain expert into the code. So there is no domain concept and code concept of the same domain concept. So any confusion is avoided about what the usage is of certain objects/classes in you code. In theory your domain expert should be able to read the name of the object and it functions and should understand what this class does.
E.g. domain experts often uses legs to describe trips between 2 destination points where cargo is transported, you should also use the concept term Legs and not Trips in the code so no confusion can be created.
This also helps to check off any possible kinks/incosistencies you have in you design by talking and refining with you domain expert. And helps add an extra layer of testing by “manually” testing togheter (by talking about the model in question) with you domain expert if your assumptions are correct. you can also automatic testing if you extract use cases out of the meeting and make test case out of it, commonly named as BDD - behavior-driven-testing.
solution space
This is the space where the actual implementation happens. Entities, value object, aggregates, … are used for this
entities
is a class which has a:
- ID
- Lifecycle (a status object)
- where a duplication of an object MATTERS. If you have an object book mapped to a physical book, duplicating that object will have dangerous side effects.
value objects
is a class which:
- does not have an ID
- can be duplicated without an problem
- is immutable
- only the properties matters e.g. money object —> amount and currency unit
aggregates
are objects which:
- can have an ID
- are treated as one
- have a transactional significance togheter, the objects should be updated in one transaction
- are NOT equal to list or maps. These aggregates have a functional significance e.g. Trips, Consultation
- should be loaded as a whole
- used for data transfer
You also have a root object in the aggregate which is the only entry point to your aggregate. Everything else should be abstracted away and be encapsulated in the aggragete itself. If you need a certain object or value you should get it from the aggregate root.
TODO
- supporting BCs
- context map vs bounded context
- intercommunication (shared kernel, open host service, client-service relation)
- DDD vs CQRS, REST
- event storming
- anemic vs feature/behavior rich object